聊聊机器学习中的那些树(4)
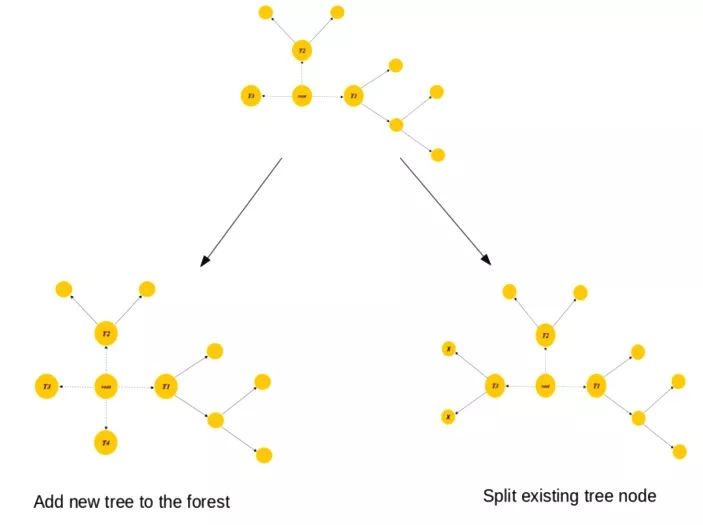
在Boost方法中,每一个被错误分类的样本的权值会增加,以强调最困难的情况,从而使得接下来的模型能集中注意力来处理这些错误的样本,然而这种方法把基于学习器的决策树视为一个黑盒子,没有利用树结构本身。而RegularizedGreedyForest正则化贪心森林(RGF)会在当前森林某一步的结构变化后,依次调整整个森林中所有决策树对应的“叶子”的权重,使损失函数最小化。例如下图我们从原来的森林中发下右下的节点可以分叉,我们做的不止是将分叉后的树加入森林,而且对森林中已有的树中的对应节点也进行类似的分叉操作。
类似boost,RGF中每个节点的权重也要不断优化,但不同的是,RGF不需要在梯度下降决策树设置所需的树尺寸(tree size)参数(例如,树的数量,最大深度)。总结一下RGF是另一种树集成技术,它类似梯度下降算法,可用于有效建模非线性关系。

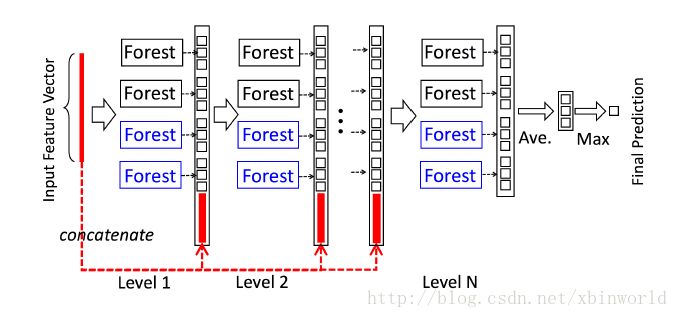
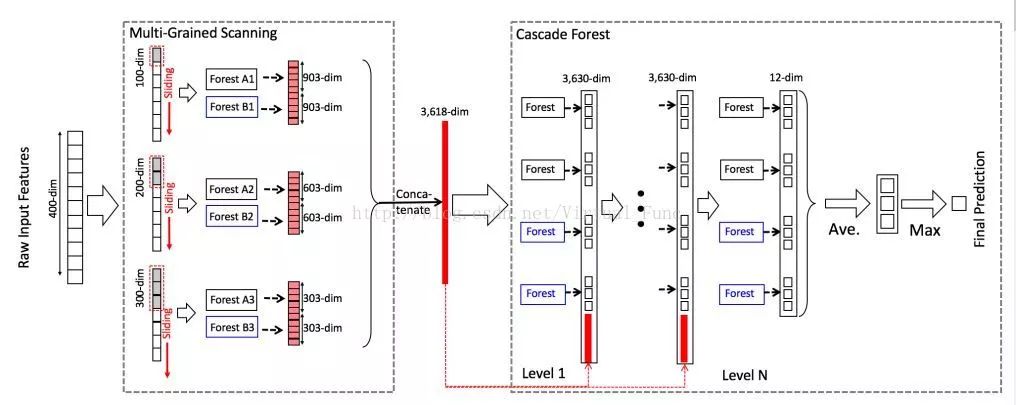
下面说说去年周志华教授提出深度森林deep forest,也叫做gcForest,这也是一种基于决策树的集成方法,下图中每一层包括两个随机森林(蓝色)和两个complete random forests(黑色),所谓complete random forest,指的是其中的1000棵决策树的每个节点都随机的选择一个特征作为分裂特征,不断增长整棵树,直到剩余所有样本属于同一类,或样本数量少于10。
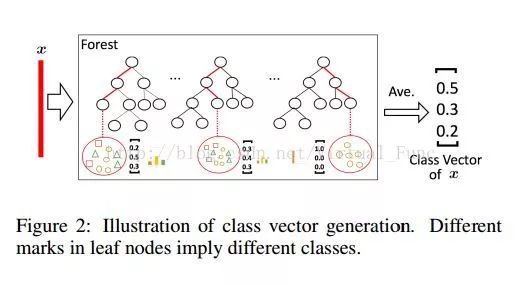
至于每一层的输出,也不是传统决策树的一个标签,而是一个向量。图中的每一个森林对每个输入样本都有一个输出,对应建立该决策树时,落在该叶子节点中的样本集合中各个类别的样本所占的比例,如下图所示,将多颗树的结果求平均,得出这一层的输出。为了避免过拟合,每个森林中 class vector 的产生采用了 k 折交叉验证的方法,随机的将k分之一的训练样本丢出去,再对k次训练的结果求平均值。
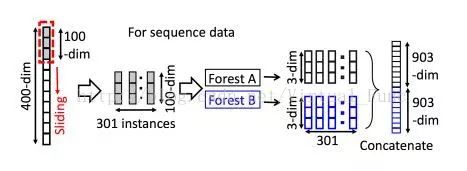
deep forest还采取了类似卷积神经网络的滑动窗口,如下图所示,原始样本的为400维,定义一个大小为100的滑动窗口,将滑动窗口从原特征上依次滑过,每次移动一步,每次窗口滑动获取的100个特征作为一个新的实例,等效于在400维特征上每相邻100维的特征摘出来作为一个特征实例,得到301个新的特征实例(400 - 300 + 1)。
深度森林的源代码也在Github上有开源版,总结一下,深度森林具有比肩深度神经网络的潜力,例如可以层次化的进行特征提取及使用预训练模型进行迁移学习,相比于深度学习,其具有少得多的超参数,并且对参数设置不太敏感,且在小数据集上,例如手写数字识别中,表现的不比CNN差。深度森林的数据处理流如下图所示。
总结下,树模型作为一个常见的白盒模型,不管数据集的大小,不管是连续的回归问题还是分类问题都适用。它不怎么需要进行数据预处理,例如补全缺失值,去除异常点。树模型可以针对特征按照重要性进行排序,从而构造新的特征或从中选出子集来压缩数据。树模型可以通过统计的方式去验证模型的准确值,判断训练的进展,相比机器学习的模型,需要调整的超参数也更少。但和神经网络一样,树模型也不够健壮,如同图像上只需要改变几个像素点就可以改变模型的结果,树模型中输入数据的微小变化也可能会显著改变模型的结果。树模型也有过拟合的危险,通过剪纸purning,即先让树长的深一些,再去除那些不带来信息增益的分叉,留下那些最初的信息增益为负,但整体的信息增益为正的节点,可以组织树模型的过拟合。