聊聊机器学习中的那些树(3)
接下来我们看一看更为复杂的情况,比如我们拿到的数据特征不是两个,而是一百个,那么问题来了,我们的决策树也要100层那么深吗?如果真的这么深,那么这个模型很容易过拟合的,任何一颗决策树的都应该有终止条件,例如树最深多少层,每个节点最少要有多少样本,最多有多少个终止节点等,这些和终止条件有关的超参数设置决定了模型会不会过拟合。

下面我们从一棵树过度到一群数,也就是机器学习中常用的bagging,将原来的训练数据集分成多份,每一份分别训练一个分类器,最后再让这些分类器进行投票表决。
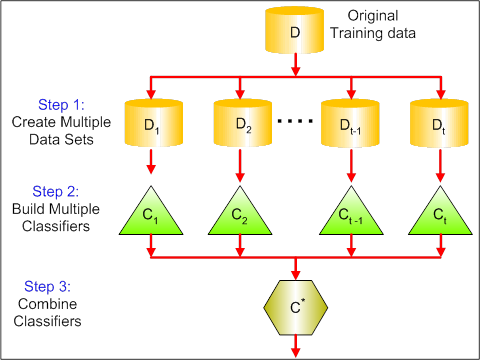
而随机森林,就是使用bagging技巧加持的决策树,是不是很简单?相比于决策树,随机森林的可解释性差一些,另外对于标签为连续的回归问题,随机森林所采取的求多个树的平均数的策略会导致结果的不稳定。
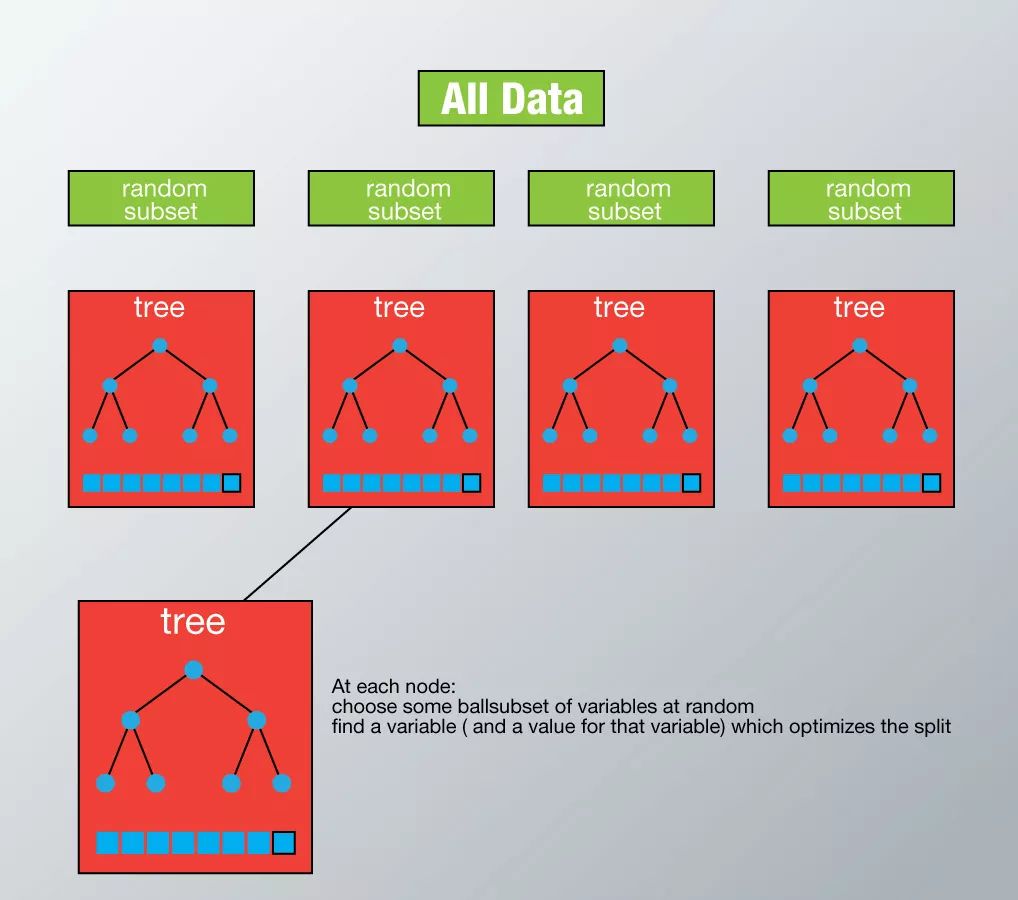
随机森林是将训练数据随机的分成很多类,分别训练很多分类器,再将这些分类器聚合起来,而boosting则不讲训练数据分类,而是将弱分类器聚合起来,下图的上半部分可以看成描述了三个弱分类器,每一个都有分错的,而将他们集合起来,可以得出一个准确率比每一个弱分类器都高的分类模型。

你需要做的是将第一个分类器分类分错的部分交给第二个分类器,再将第二个分类器分错的部分交给第三个分类器,如下图依次所示
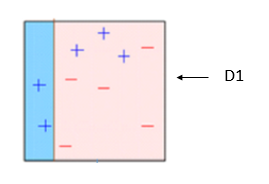
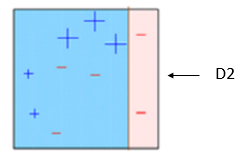
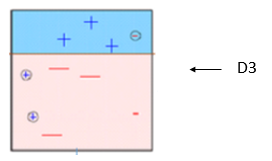
最终得到了我们看到的强分类器。
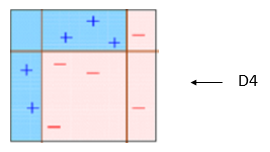
总结来看,begging类似于蚁群的智慧,没有一只蚂蚁知道全部的信息,但利用蚂蚁的集合,可以实现集愚成智,而boosting则是三个臭皮匠,胜过诸葛亮。Boost方法包含的非线性变换比较多,表达能力强,而且不需要做复杂的特征工程和特征变换。但不同于随机森林,它是一个串行过程,不好并行化,而且计算复杂度高。
XGBoost 是 Extreme Gradient Boosting (极端梯度上升)的缩写,是当下最常用的树模型了,是上图描述的Boosting Tree的一种高效实现,在R,Python等常用的语言下都有对应的包,它把树模型复杂度作为正则项加到优化目标中,从而避免了过于复杂而容易过拟合的模型。